Home ➤ Blog ➤ Marketing Tactics ➤ Building ML Models for Qualifying Leads
Building ML Models for Qualifying Leads
Alec Foster • 2023-08-14
Marketing Tactics, AI Models
FairShake is a beacon of support for Americans who need assistance with a corporate dispute. In an era where individuals often feel overwhelmed by the complex consumer arbitration process, FairShake provides a means to redress grievances.
My journey at FairShake was marked by the pursuit of technological excellence to streamline the process of handling these grievances. We aimed to deliver a more responsive, accurate, and fair system that respected the rights of the individual while enhancing our operational efficiency.
The Challenge
The challenge we faced was twofold. On one hand, we needed to reduce the time and effort required to process claims, and on the other, we had to ensure that the process remained just and unbiased. The balance between efficiency and ethics guided our entire approach.
The Journey to Building Effective Models
Phase 1: Initial Exploration
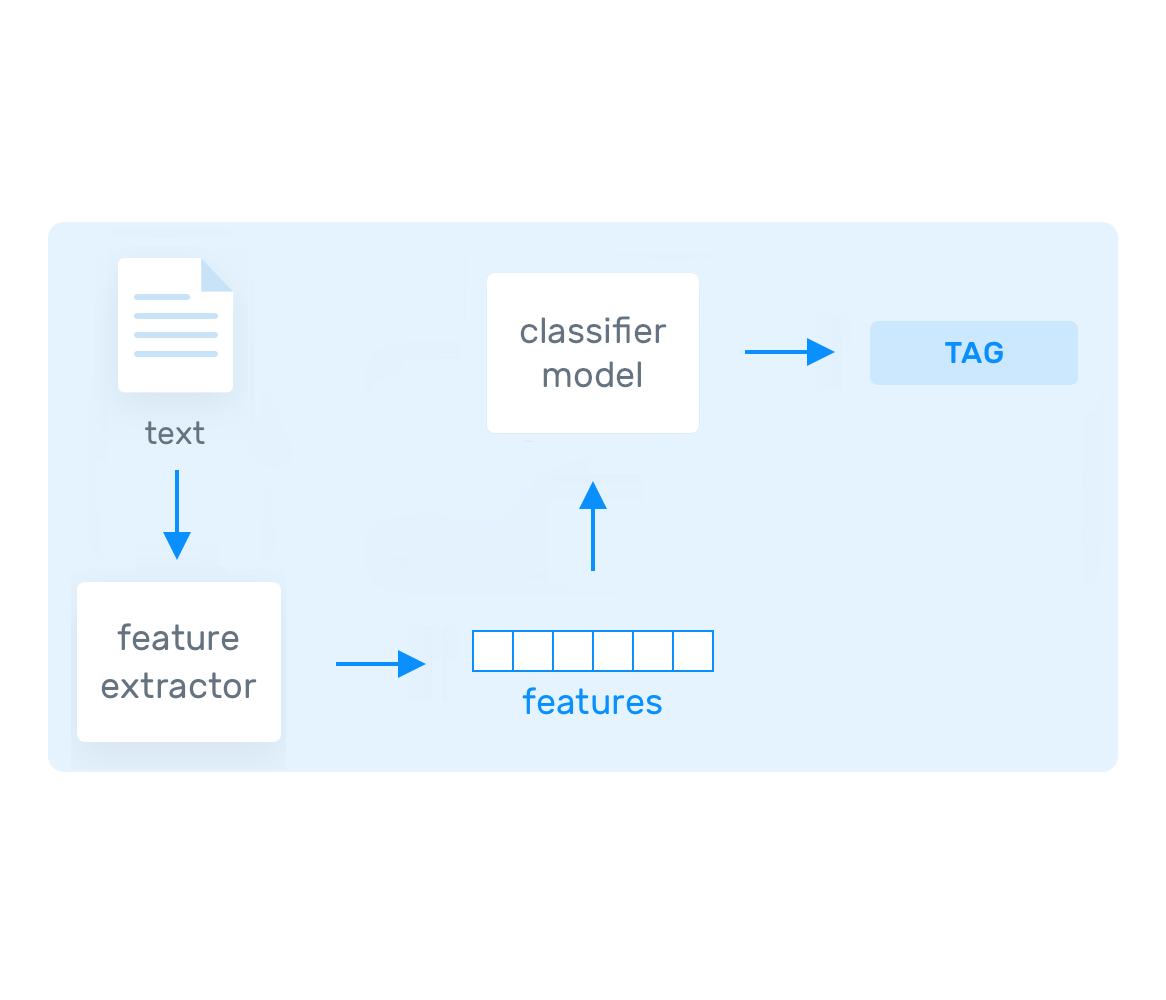
My initial efforts involved using MonkeyLearn to create text classifiers for different verticals. After uploading thousands of claim texts tagged as "approve" and "reject," I found that the model's accuracy was no better than our existing remote CX team.
A deep dive into the data revealed a troubling number of false positives and negatives. It was clear that to enhance accuracy, a comprehensive review of each piece of data was essential.
Phase 2: Refinement and Focus
Though the initial models were not ready for deployment, they provided valuable insights into the data's inconsistencies. This discovery led me to export the data and reduce the dataset size to a more manageable 1000 examples per classification.
I ensured that the data covered all types of rejections, including ones based on specific criteria like excessive profanity, and chose appropriate classification algorithms, such as Naive Bayes and Support Vector Machines (SVMs).
Naive Bayes
This technique calculates the probability that a data point belongs to a certain category. In our context, it helped categorize words or phrases as belonging to a preset tag.
Support Vector Machines
SVMs classify data within degrees of polarity and assign a hyperplane that separates the tags. In testing, I found the Naive Bayes algorithm to be more accurate due to the complexity of our data set.
Phase 3: Continuous Improvement and Ethical Considerations
I supervised the models' classifications for months, conducting an audit to eliminate biases against claimants with lower education levels or those using African American Vernacular English (AAVE). The drive for equitable treatment extended to ensuring accuracy for Spanish-language claims as well.
Further improvements came by adding additional tags to the data, such as financial harm, specific contact information, and specific demand for restitution. This nuanced tagging enabled the models to understand the training data better.
Outcomes
The implementation of these machine learning models led to impressive results:
- 50% Reduction in Claimant Waiting Time: A faster process meant quicker justice.
- 70% Improvement in Assignment Accuracy: Enhanced accuracy ensured that claims were treated fairly and precisely.
- 20 Weekly Moderation Hours Saved: Streamlined operations freed up valuable human resources.
- Ethical Assurance: By retaining human oversight for claims the model marked for rejection, we maintained a balance between efficiency and justice.
Conclusion
My tenure at FairShake illustrates how AI, guided by empathy and intelligence, can transform a process. The machine learning models we implemented not only made our operations more efficient but also ensured that they remained grounded in principles of fairness and equity. The balance between enhancing business outcomes and responsible AI is a testament to the power of technology for societal good.


